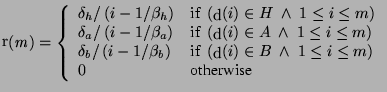| (1) |
The authors conducted `Web Retrieval Task' ('NTCIR-3 WEB') from 2001 to 2002 at the Third NTCIR Workshop. In the NTCIR-3 WEB, they evaluated on searches using various types of user input, user models and document models. As the document data sets, they constructed 100- and 10-gigabyte document collections that were gathered from the `.jp' domain. The user input was given as query term(s), sentence, and document(s). They assumed two user models where comprehensive relevant documents are required, and where precision of the top-ranked results is emphasized. They also assumed several document models, such as a document as an individual page, and a document as a page set connected by hyperlinks. This paper discusses evaluation methods taking hyperlink structure into consideration, which is one of the distinctive proposals made in NTCIR-3 WEB. Through the evaluation results, they suggested that the link-based techniques perform effectively when short queries are input.
Evaluation methods, Test collections, Web information retrieval
This paper discusses evaluation methods considering hypelink structure, which were proposed in `NTCIR-3 WEB' [3,2,8]. In the NTCIR-3 WEB, we attempted to assess the retrieval effectiveness of Web search engine systems using a common data set, and to build re-usable test collections that are suitable for evaluating Web information retrieval systems. TREC Web Tracks [4] are well-known workshops that have an objective to research the retrieval of large-scale Web document data. They assessed the relevance only on information given in English text, not considering hyperlinks. The NTCIR-3 WEB was another workshop that used 100- and 10-gigabyte document data mainly gathered from the `.jp' domain. Relevance judgment was performed on the retrieved documents that were written in Japanese or English, partially considering hyperlinks. By considering the hyperlinks, not only `authority pages' but also `hub pages' [7] may be judged as relevant.
The NTCIR-3 WEB was composed of the following tasks for the two document data sets: (I) 100 gigabytes, and (II) 10 gigabytes, respectively.
The Survey Retrieval Tasks assumed the user model where the user attempts to comprehensively find documents relevant to his/her information needs. Three types of query were supposed: query term(s) and sentence as `Topic Retrieval Task', and query document(s) as `Similarity Retrieval Task'. The Topic Retrieval Task is similar to a traditional ad-hoc retrieval [4,6], and so ensures the reusability of the test collection. The participants in the Topic Retrieval Task had to submit at least two lists of their run results: that of the run using only the topic field of TITLE and that of the run using only DESC, which are mentioned in Section 3.2.
The Target Retrieval Task aimed to evaluate the effectiveness of the retrieval, supposing a user model where the user requires just one answer, or only a few answers. The precision of the highly ranked search results was emphasized in this study. The runs were evaluated using the 10 top-ranked documents retrieved for each topic. The mandatory runs were the same as those of the Topic Retrieval Task.
We constructed test collections that were suitable for evaluating Web information retrieval systems (`Web test collections'), and that were composed of: (i) the document set, (ii) the topics, and (iii) the list of relevance judgment results for each topic.
In the NTCIR-3 WEB, we prepared two types of document data gathered from the `.jp' domain, limiting to HTML or plain text files: (a) document data over 100 gigabytes (`NW100G-01'), and (b) 10-gigabyte subset data (`NW10G-01'). Almost all the documents were written in Japanese or English, but some were written in other languages. We also provided two separate lists of documents that were connected from the individual documents included in (a) and (b), but not limited to the `.jp' domain. These four data sets were used for searching in the NTCIR-3 WEB [2].
The organizers provided `topics' that were statements of information needs. The topic format was basically inherited from previous NTCIR Workshops [6], except for some modifications [2]. The most important parts of the topic are TITLE and DESC. The TITLE provided up to three terms that were specified by the topic creator, simulating the query terms in real Web search engines. The DESC (`description') represented the most fundamental description of the user's information needs in a single sentence. All of the topics were written in Japanese.
We performed `pooling,' which took the top 100 ranked documents from each run result and merged them, as in the pooling methods previously used in TRECs or NTCIR Workshops [4,6]. Through the pooling stage, we obtained a subset of the document data, called the `pool'. Human assessors judged the `multi-grade relevance' of the individual documents in the pool as: highly relevant, fairly relevant, partially relevant, or irrelevant, using three document models described below. (i) `One-click-distance document model' was where the assessor judged the relevance of a page when he/she could browse the page and its out-linked pages that were included in the pool, assuming that most of the relevant documents were included in the pool. (ii) `Page-unit document model' was where the assessor judged the relevance of a page only on the basis of the entire information given by it, as is performed conventionally [4,6]. (iii) `Passage-unit document model' was where the assessor specified the passages that provided evidence of relevance, which he/she used to judge the passages relevant.
In evaluating the run results of each participant's system, we applied several evaluation measures as described below. For the Survey Retrieval Tasks, we used the following measures: `average precision (non-interpolated)' (aprec), `R-precision' [1] (rprec)1, and `DCG' [5] after 100 documents were retrieved (dcg(100))2. For the Target Retrieval Task, we used the following measure: `document-level precision' (prec(10)), DCG (dcg(10)) and `weighted reciprocal rank' (wrr(10)) under the conditions of cut-off levels of 10.
The weighted reciprocal rank (`WRR') was extended from `mean
reciprocal rank' [9] (`MRR') to be suitable for
multi-grade relevances, as the mean value of the wrr(m) defined by
the following equations over all the topics3:
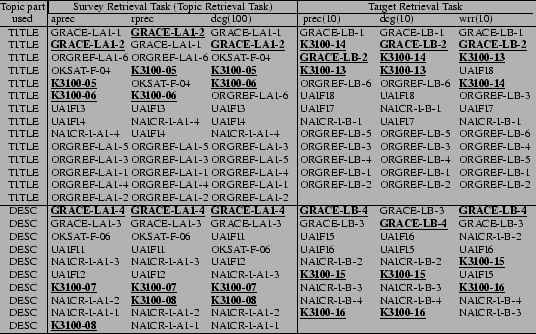
Six groups submitted their completed run results4, with the organizers also submitting the results from their own search system along with those of the participants in an attempt to improve the comprehensiveness of the pool. For the Survey Retrieval Task and the Target Retrieval Task against 100-gigabyte data, we ranked the run results in order of the several evaluation measures using the one-click-distance document model, as shown in Table 1.
Focusing on the Target Retrieval Task (the right part of the table), we observed the distribution of run IDs that were carried out by the systems based on not only page content but also hyperlink information (underlined run ID codes). As the results, it suggests that the link-based systems perform more effectively with short queries such as the TITLEs than longer queries such as the DESCs. Moreover, focusing on the TITLE-only runs in both tasks (the upper part of the table), we compared the distribution of underlined run ID codes. As the results, it suggests that the link-based systems using short queries perform more effectively for highly ranked documents such as in the Target Retrieval Task than for entire ranked results such as in the Survey Retrieval Task5.
We have described evaluation methods considering hyperlink structure, which are proposed in `NTCIR-3 WEB'. Through evaluating the run results submitted by the participants, we observed that the link-based techniques perform effectively using short queries within highly ranked documents. The detailed analysis of the evaluation results is one of our tasks for future work.
This work was partially supported by Japanese MEXT Grants-in-Aid for Scientific Research on Priority Areas of ``Informatics'' (#13224087) and for Encouragement of Young Scientists (#14780339). We greatly appreciate the efforts of all the participants and the useful advice of the Advisory Committee of the NTCIR-3 WEB.