Note: We strongly recommend printing the PDF version of this paper.
Copyright is held by the
author/owner(s).
WWW2003, May 20-24, 2003, Budapest, Hungary.
ACM 1-58113-680-3/03/0005.
Information retrieval has recently witnessed remarkable advances, fueled almost entirely by the growth of the web. The fundamental feature distinguishing recent forms of information retrieval from the classical forms [25] is the pervasive use of link information [3] [5]. Drawing upon the success of search engines that use linkage information extensively, we study the feasibility of extending link-based methods to new application domains.
Interactions between individuals have two components:
Making determinations about values, opinions, biases and judgments purely from a statistical analysis of text is hard: these operations require a more detailed linguistic analysis of content [24] [28]. However, relatively simple methods applied to the link graph might discern a great deal.
We selected the mining of newsgroup discussions as our sandbox for this study. We chose this domain for the following reasons.
Quotation links have several interesting social characteristics. First, they are created without mutual concurrence: the person quoting the text does not need the permission of the author to quote. Second, in many newsgroups, quotation links are usually "antagonistic": it is more likely that the quotation is made by a person challenging or rebutting it rather than by someone supporting it. In this sense, quotation links are not like the web where linkage tends to imply a tacit endorsement.
Our target application is the categorization of the authors on a given topic into two classes: those who are "for" the topic and those who are "against". We develop a graph-theoretic algorithm for this task that completely discounts the text of the postings and only uses the link structure of the network of interactions. Our empirical results show that the link-only algorithm achieves high accuracy on this hard problem.
Figure 1 shows an example of the results produced by our algorithm when applied to social network extracted from newsgroup discussions on the claim handling of a specific insurance company.
The work of pioneering social psychologist Milgram [19] set the stage for investigations into social networks and algorithmic aspects of social networks. There have been more recent efforts directed at leveraging social networks algorithmically for diverse purposes such as expertise location [17], detecting fraud in cellular communications [9], and mining the network value of customers [8]. In particular, Schwartz and Wood [26] construct a graph using email as links, and analyze the graph to discover shared interests. While their domain (like ours) consists of interactions between people, their links are indicators of common interest, not antagonism.
Related research includes work on incorporating the relationship between objects into the classification process. Chakrabarti et al. [6] showed that incorporating hyperlinks into the classifier can substantially improve the accuracy. The work by Neville and Jensen [22] classifies relational data using an iterative method where properties of related objects are dynamically incorporated to improve accuracy. These properties include both known attributes and attributes inferred by the classifier in previous iterations. Other work along these lines include co-learning [2] [20] and probabilistic relational models [10]. Also related is the work on incorporating the clustering of the test set (unlabeled data) when building the classification model [13] [23].
Pang et al. [24] classify the overall sentiment (either positive or negative) of movie reviews using text-based classification techniques. Their domain appears to have sufficient distinguishing words between the classes for text-based classification to do reasonably well, though interestingly they also note that common vocabulary between the two sides limits classification accuracy.
The rest of the paper is organized as follows. In Section 2, we give a graph theoretic formulation of the problem. We present results on real-life datasets in Section 3, including a comparison with alternate approaches. Section 4 describes sensitivity experiments using synthetic data. We conclude with a summary and directions for future work in Section 5.
Consider a graph ![]() where the vertex set
where the vertex set ![]() has a vertex per
participant within the newsgroup discussion. Therefore the total
number of vertices in the graph is equal to the number of distinct
participants.
An edge
has a vertex per
participant within the newsgroup discussion. Therefore the total
number of vertices in the graph is equal to the number of distinct
participants.
An edge ![]() ,
,
![]() , indicates that person
, indicates that person ![]() has
responded to a posting by person
has
responded to a posting by person ![]() .
.
Optimum Partitioning
Consider any bipartition of the vertices into two sets ![]() and
and ![]() , representing those for and
those against an issue. We assume
, representing those for and
those against an issue. We assume ![]() and
and ![]() to be disjoint and
complementary, i.e.,
to be disjoint and
complementary, i.e., ![]() and
and
![]() .
Such a pair of sets can be associated with the cut function,
.
Such a pair of sets can be associated with the cut function,
![]() , the number of edges crossing from
, the number of edges crossing from ![]() to
to
![]() . If most edges in a newsgroup graph
. If most edges in a newsgroup graph ![]() represent disagreements, then the following holds:
represent disagreements, then the following holds:
For such a choice of ![]() and
and ![]() , the edges
, the edges
![]() are
those that represent antagonistic responses, and the remainder of the
edges represent reinforcing interactions. Therefore, if one were to
have an algorithm for computing
are
those that represent antagonistic responses, and the remainder of the
edges represent reinforcing interactions. Therefore, if one were to
have an algorithm for computing ![]() and
and ![]() optimizing
optimizing ![]() as above,
then we would have a graph theoretic approach to classifying people in
the newsgroup discussions based solely on link information.
as above,
then we would have a graph theoretic approach to classifying people in
the newsgroup discussions based solely on link information.
This problem, known as the max cut problem, is known to be
NP-complete, and indeed was one of those shown to be so by
Karp in his landmark paper [15]. The situation on the problem
remained unchanged until 1995, when Goemans and Williamson [11] introduced
the idea of using methods from Semidefinite Programming to approximate
the solution with guaranteed bounds on the error better than the naive
value of ![]() .
Semidefinite programming methods involve a lot of machinery, and in
practice, their efficacy is sometimes questioned [14].
.
Semidefinite programming methods involve a lot of machinery, and in
practice, their efficacy is sometimes questioned [14].
Efficient Solution Rather than using semidefinite approaches, we will resort to spectral partitioning [27] for computational efficiency reasons. In doing so, we exploit particularly two additional facts that hold in our situation:
In such situations, we can transform the problem into a min-weight approximately balanced cut problem, which in turn can be well approximated by computationally simple spectral methods. We detail this process next.
Consider the co-citation matrix of the graph ![]() . This graph,
. This graph, ![]() is a graph on the same set of vertices as
is a graph on the same set of vertices as ![]() . There is a
weighted edge
. There is a
weighted edge
![]() in
in ![]() of weight
of weight ![]() if and only if
there are exactly
if and only if
there are exactly ![]() vertices
vertices
![]() such that each edge
such that each edge ![]() and
and ![]() is in
is in ![]() . In other words,
. In other words, ![]() measures the
number of people that
measures the
number of people that ![]() and
and ![]() have both responded to.
Clearly,
have both responded to.
Clearly, ![]() can be used as
a measure of "similarity", and we can use spectral (or any other) clustering
methods to cluster the vertex set into classes. This leads to the
following observations.
can be used as
a measure of "similarity", and we can use spectral (or any other) clustering
methods to cluster the vertex set into classes. This leads to the
following observations.
A limitation of the approach discussed so far is that while high accuracy implies high cut weight, the reverse may not be necessarily true. We may need to embellish our partitioning algorithms with some focusing to nudge them towards partitions that have high cut weight as well as high accuracy.
The basic idea will be to manually categorize a small number of prolific posters and tag the corresponding vertices in the graph. We then use this information to bootstrap a better overall partitioning by enforcing the constraint that those classified on one side by human effort should remain on that side during the algorithmic partitioning of the graph. We can now define the constrained graph partitioning problem:
We can achieve the above partitioning by using a simple artifice: all the positive vertices are condensed into a single vertex, and similarly for the negative vertices, before running the partitioning algorithm. Since EV and EV+KL algorithms cannot split the single vertex, all we need to check is that the final result has these two special vertices on the correct sides. The corresponding algorithms will be referred to as the Constrained EV and Constrained EV+KL algorithms.
We next present the results of our empirical evaluation of the link-only approach.
|
Because of the sampled nature of the data, if we were to form the graph corresponding to all the responses, parts of the graph would contain too little information to be analyzed effectively [26]. Each data set contained a core connected component (see Figure 3) that comprised almost all the postings within the data set. We, therefore, omitted all vertices (and corresponding documents) that do not connect to the core component. Figure 3 also shows the total number of authors and the average number of postings per author in the core component.
|
To understand the nature of links in the newsgroups, we manually examined 100 responses (split equally between the three datasets). We found two interesting behaviors:
|
For each dataset, we manually tagged about 50 random people (not postings) into "positive" and "negative" categories to generate the test set for our experiments. Figure 5 gives the number of people in each category for the three datasets.
|
Before presenting results for the graph-theoretic approach, we first give results obtained using two classification-based approaches: text classification and iterative classification. These results should be viewed primarily as reference points for whether link-based methods can yield good results.
We experimented with two commonly used text classification methods: Support Vector Machines [4] [29] and Naive Bayes classifiers [12] [21]. For SVM, we used Ronan Collobert's SVMTorch II [7]. For Naive Bayes, we used the implementation described in [1].
The training set for text-based classification was obtained by taking the postings of each of the manually tagged user and treating them as one document (after dropping quoted sections). The 10-fold cross-validation results for both Naive Bayes and SVM are shown in Figure 6(b). We also show in Figure 6(a) the accuracy for the three datasets if everyone was simply assigned to the majority class.
|
Both SVM and Naive Bayes were unable to distinguish the two classes, for any of the datasets. The only apparent exception is the 72% accuracy on Gun Control with Naive Bayes; however, this result was obtained by classifying all examples into the majority class. The reason for the low accuracy is that in a newsgroup discussion the vocabulary used by two sides is quite similar. Meaningful words are contained equally frequently in both the positive and negative classes, and the "distinguishing words" are meaningless.1
Next, we experimented with an algorithm based on the iterative classification
proposed in [22].
The proposal in [22]
used both the text as well as the link structure.
However, given the inadequate accuracy of the text-based classifiers, we
experimented with
a purely link-based version, which we describe next.
Let the total number of iterations be ![]() . In each iteration
. In each iteration ![]() :
:
Let ![]() be the weight of the link between vertices
be the weight of the link between vertices ![]() and
and ![]() .
Let the vertices in the training set have scores of either +1 or -1
(depending on their class). The score for labeled vertices in the test
set is their score in the previous iteration; the score for unlabeled
vertices is 0.
The score
.
Let the vertices in the training set have scores of either +1 or -1
(depending on their class). The score for labeled vertices in the test
set is their score in the previous iteration; the score for unlabeled
vertices is 0.
The score ![]() for a vertex
for a vertex ![]() in the test set is computed as:
in the test set is computed as:
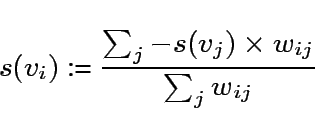
The sign of ![]() gives the predicted class label, and
gives the predicted class label, and ![]() gives the confidence of the prediction.
gives the confidence of the prediction.
Figure 6(c) gives the 10-fold cross-validation results for this algorithm. Clearly, iterative classification using the link structure does much better than the text-based classification. In some sense, this algorithm can be considered as a heuristic graph partitioning algorithm. Thus the question is: will the traditional graph partitioning algorithms do better than this heuristic approach?
Figure 6(d) shows accuracy results obtained using the unconstrained EV and EV+KL algorithms for the three datasets. Unlike the two earlier approaches, unconstrained partitioning does not need the manually-labelled postings as training data; thus the accuracy was computed simply by checking how many labeled individuals were assigned correct partitions.
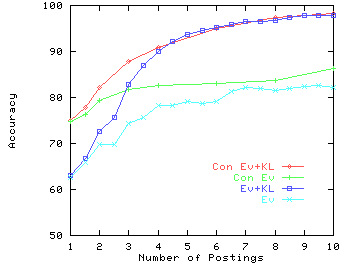
Note that the iterative classification algorithm should really be compared to the constrained graph partitioning algorithm (that also uses training data), not the unconstrained graph partitioning. Nevertheless, it is quite interesting that even unconstrained graph partitioning does quite well on two of the datasets: Abortion and Gun Control. It does about as well as iterative classification, and much better than text-based classification. We will explain shortly why the accuracy obtained is not high for the third dataset (Immigration). KL marginally improves EV for Abortion and Immigration, but degrades EV for Gun Control.
Although the results for Gun Control are not that much better than assigning everything to the majority class, these results were not obtained by assigning everything to the majority class. In fact, all the errors were due to the misassignments of majority class to minority class. This phenomenon can be explained as follows. When the distribution of classes is skewed, it is quite likely that there will be some majority class people who will interact more with other majority class people than with the minority class. So they will be misclassified. On the other hand, most of the minority class people will be correctly classified since they will interact much more with the majority class.
To understand why EV did not do well on Immigration, we ran KL 1000 times starting with different random partitions, and measured cut weight versus accuracy. The results are shown in Figure 7. This figure confirms the observation we made in Section 2 that high accuracy implies high cut weight, but not vice versa. For Immigration, accuracy for a cut weight of 84% ranges between 50% and 87%. We therefore need to use constrained partitioning to nudge EV towards partitions that have high cut weight as well as high accuracy.
Figure 6(e) shows the result of 10-fold cross-validation obtained by choosing different small subsets of the hand classified vertices as the manually tagged ones. We see that the accuracy results (compared to unconstrained graph partitioning) are now about the same for Abortion, better for Gun Control, and dramatically better for Immigration. Constrained graph partitioning does consistently (4% to 6%) better than iterative classification on all three datasets.
In this section, we explore the impact of various data set parameters on the performance of the algorithms. Since it is infeasible to obtain real world data for a variety of parameter settings, we resort to synthetic data. We do this study largely to verify that the proposed algorithms are not dependent on some peculiarities of the datasets used in the experiments, and do work under a variety of settings.
Figure 8 gives the baseline parameters used
to create the synthetic datasets. We chose to make our classes
unbalanced, i.e. 60% of the users are chosen in the majority (in our
case, positive) class. Purity ![]() is the fraction of links that cross
from one class to the other;
i.e. purity determines the expected number of antagonistic links
in the network.
is the fraction of links that cross
from one class to the other;
i.e. purity determines the expected number of antagonistic links
in the network.
|
The following is a description of the data generation algorithm.
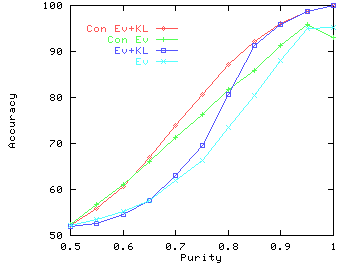
In the second experiment, we hold the average number of postings per
author fixed at 3 and vary purity parameter ![]() . Since the number of
postings per user is small, the number of users with more antagonistic
links than reinforcement links largely follows the purity fraction, and
correspondingly accuracy also follows purity, as shown in
Figure 11.
. Since the number of
postings per user is small, the number of users with more antagonistic
links than reinforcement links largely follows the purity fraction, and
correspondingly accuracy also follows purity, as shown in
Figure 11.
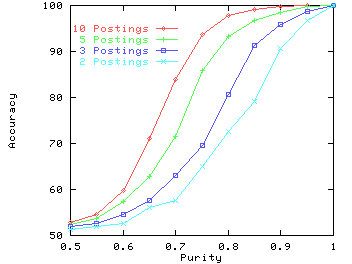
However, when the number of postings is large, we can get high accuracies even if a large fraction of interactions are between people on the same side. The explanation is the same as that for the first experiment. Figure 12 shows the accuracy of the EV+KL algorithm for average number of postings ranging from 2 to 10, and purity ranging from 0.5 to 1. Notice that even for a low purity of 0.7 (where 30% of the postings are between people on the same side), we are able to get an accuracy of 85% when there are 10 postings per user. At a purity of 0.8, we get 98% accuracy. Thus, given sufficient interactions, the algorithm is undisturbed by a substantial fraction of reinforcement links.
We developed a links-only algorithm for this task that exhibited significant accuracy advantage over the classical text-based algorithms. These accuracy results are quite interesting, particularly when one considers that we did not even ascertain whether a response was antagonistic or reinforcing, for that would have violated the no-looking-into-the-text dictum. We simply assumed that all links in the network were antagonistic. As long as the number of reinforcing responses are relatively few, or there are enough postings per author, the algorithm can withstand this error in building the network.
For future work, it will be interesting to explore if the accuracy of the proposed techniques can be further improved by incorporating advanced linguistic analysis of the text information. More generally, it will be interesting to study other social behaviors and investigate how we can take advantage of links implicit in them.
Acknowledgments We wish to thank Xianping Ge for his help with the text-based classification experiments.
![\begin{figure*}\centering
\psfig{file=/www03.social/graphs/eps/sf-claim.eps,width=6in} \\ [3ex]
\vspace{-1ex}\end{figure*}](img3.gif)
![\begin{figure}\centering
Immigration \\ [.5ex]
\psfig{file=/www03.social/graphs/eps/immig-kl.eps,width=3.0in}\end{figure}](img44.gif)
![\begin{figure}\centering
Gun Control \\ [.5ex]
\psfig{file=/www03.social/graphs/eps/gun-post-rf.eps,width=3.0in}\end{figure}](img50.gif)